Audio Samples and Beampatterns – Linearly Constrained Deep Beamformer for Multi-Speaker Scenarios
Ilai Zaidel, Ori Engel, Bar Engel, and Sharon Gannot
We propose a deep beamforming framework for enhancing target speaker(s) in multi-speaker environments.
A deep neural network (DNN) is trained to estimate beamforming weights directly from noisy multichannel
inputs while satisfying linear spatial constraints through an adaptive multi-term loss inspired by the
augmented Lagrangian framework. The loss combines signal reconstruction with penalties that enforce a
distortionless response toward the target and suppress the interference subspace. The model is further
guided by the target relative transfer function (RTF) and the estimated interference subspace.
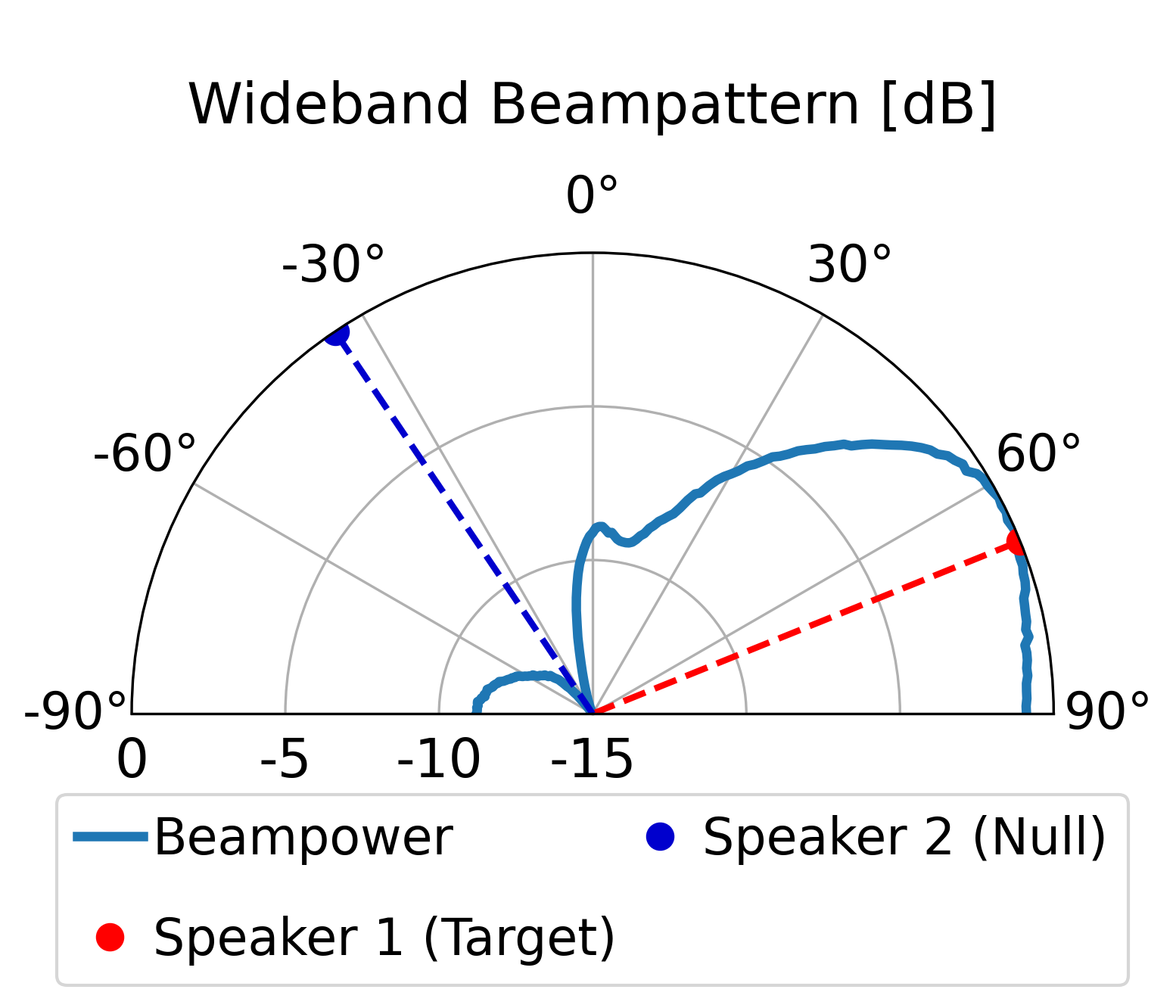
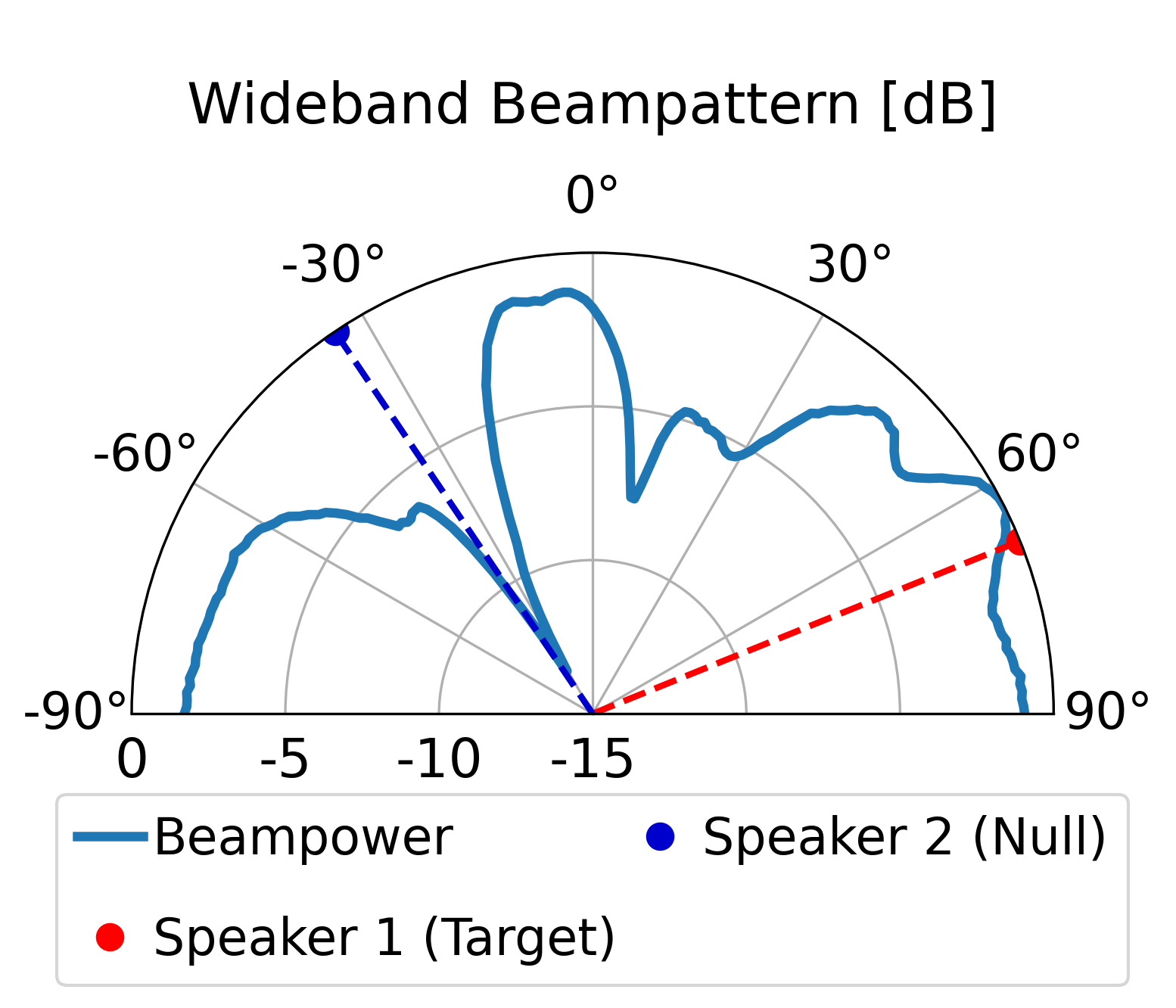
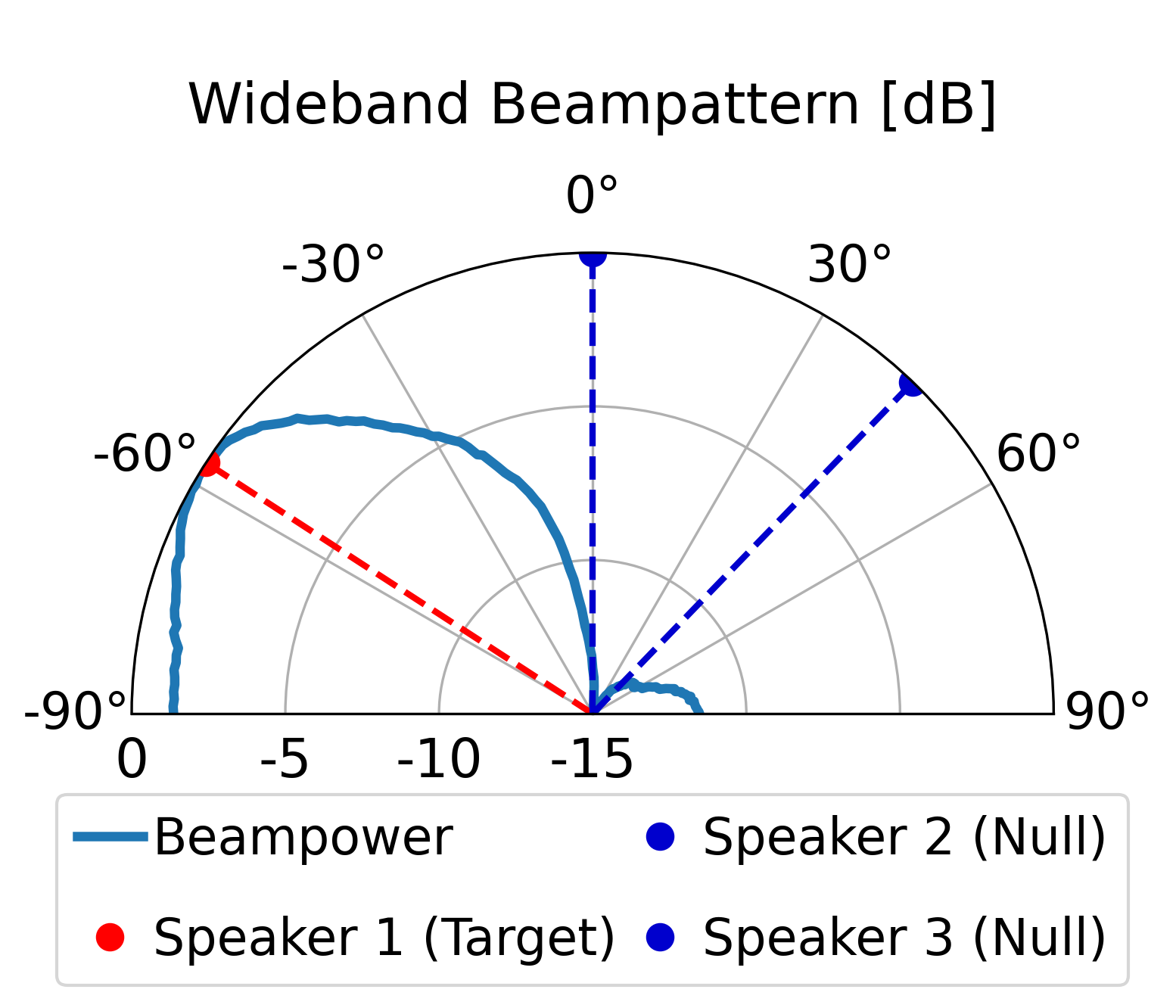
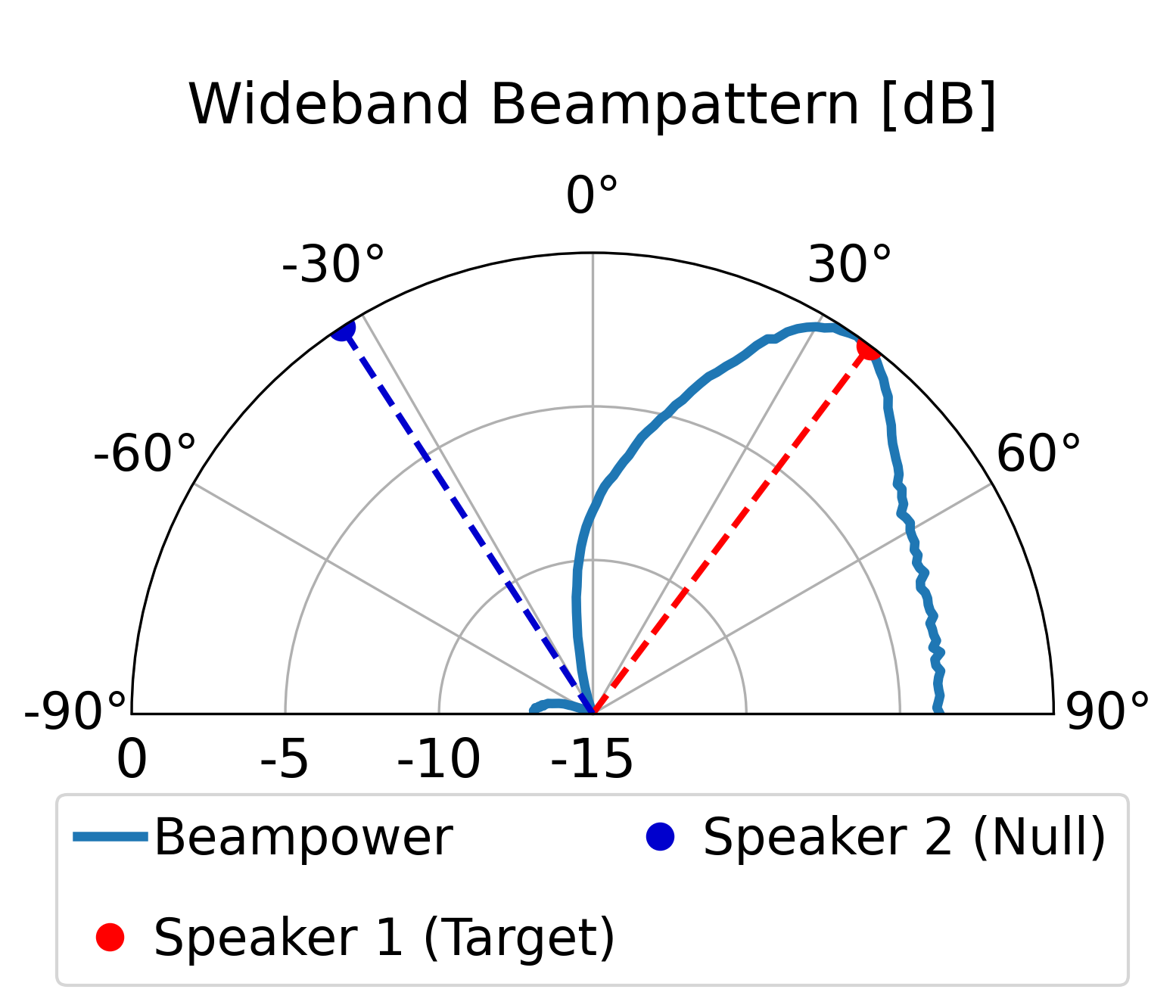
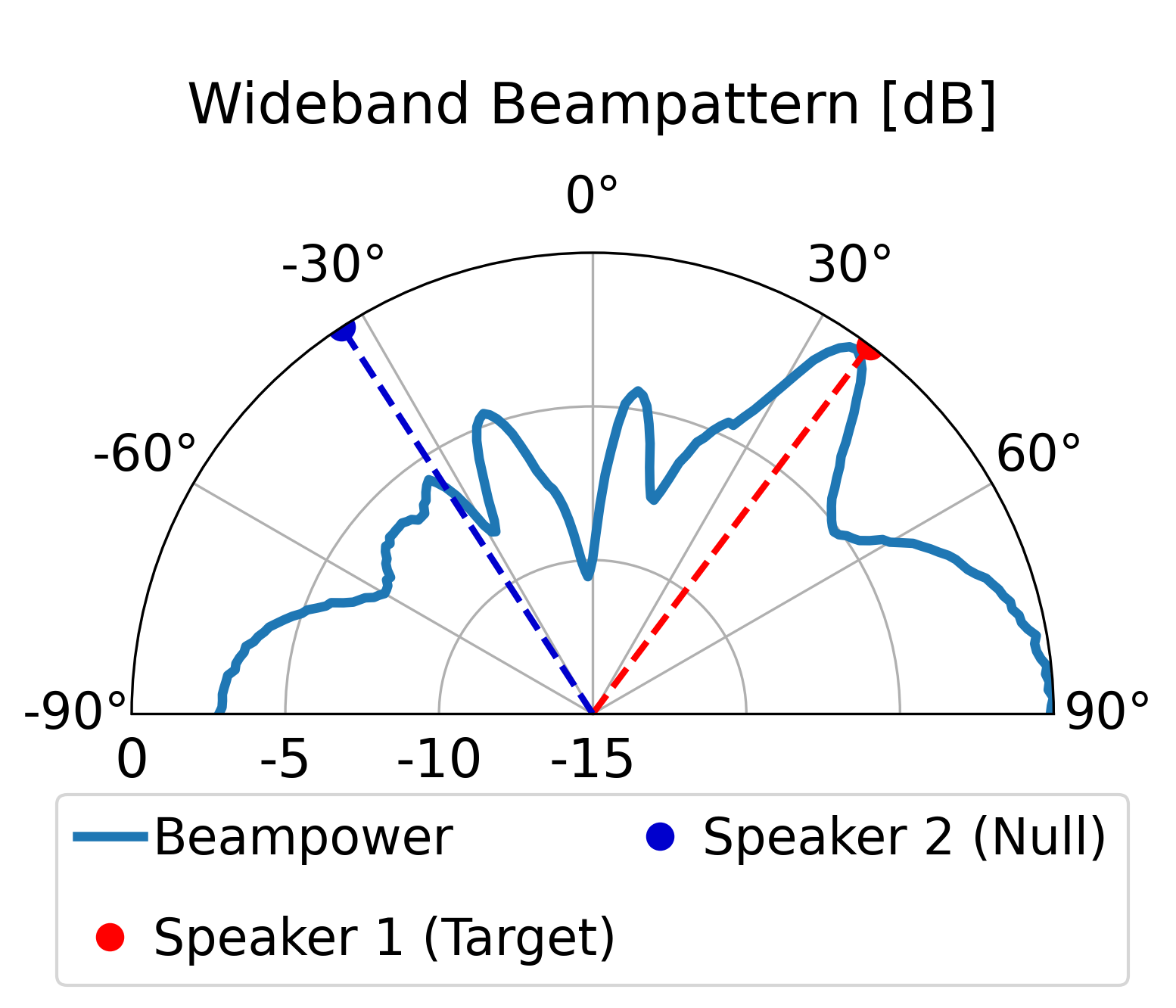
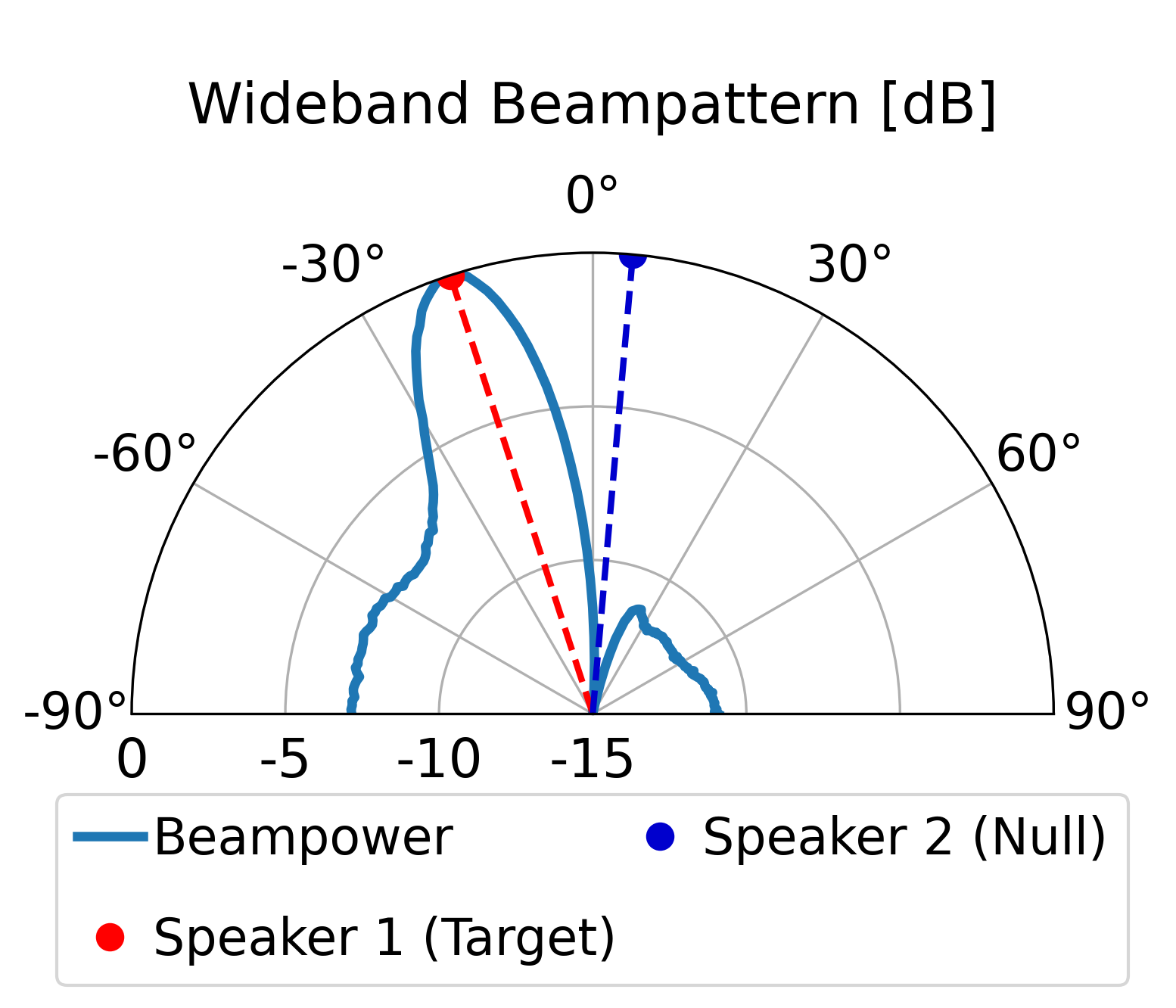
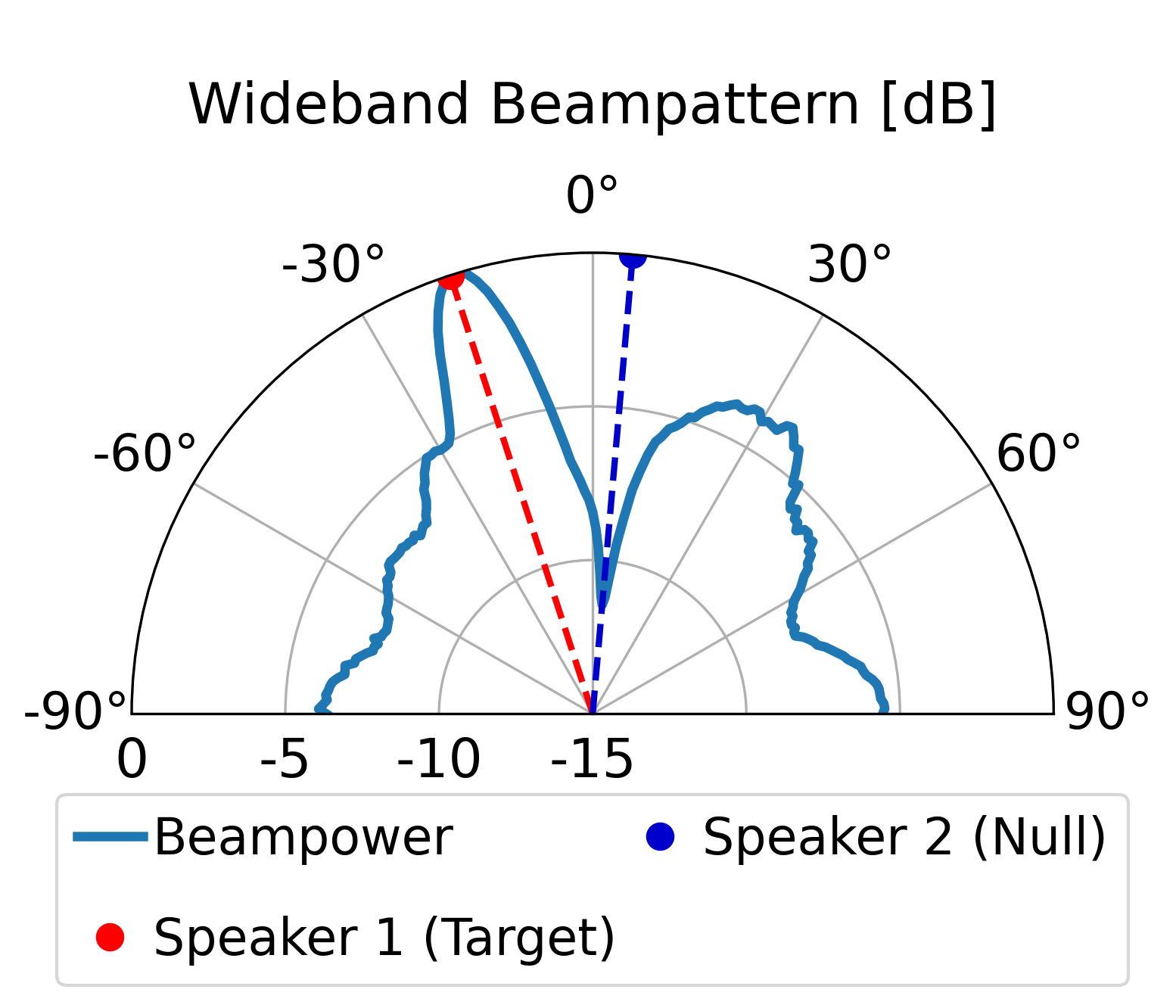
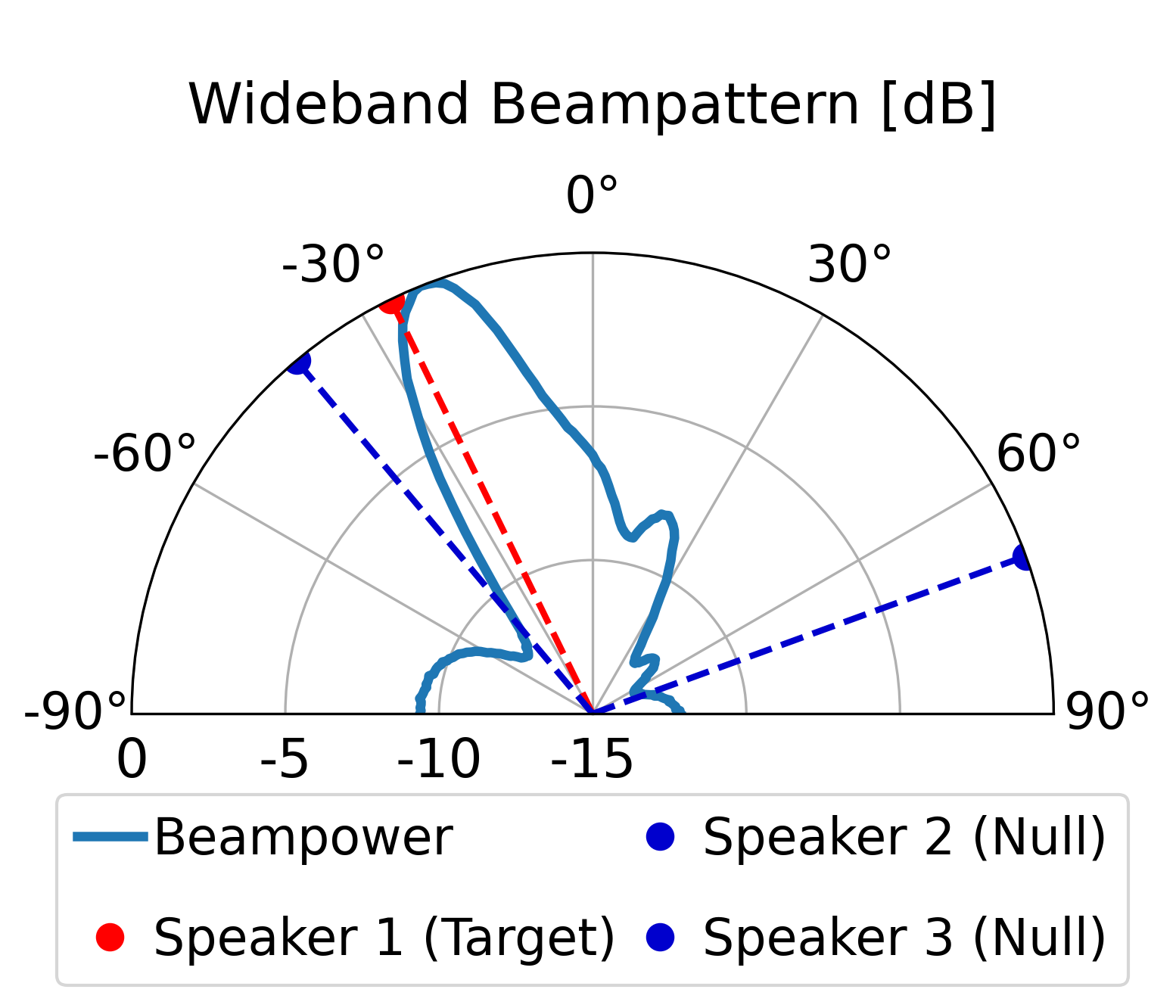
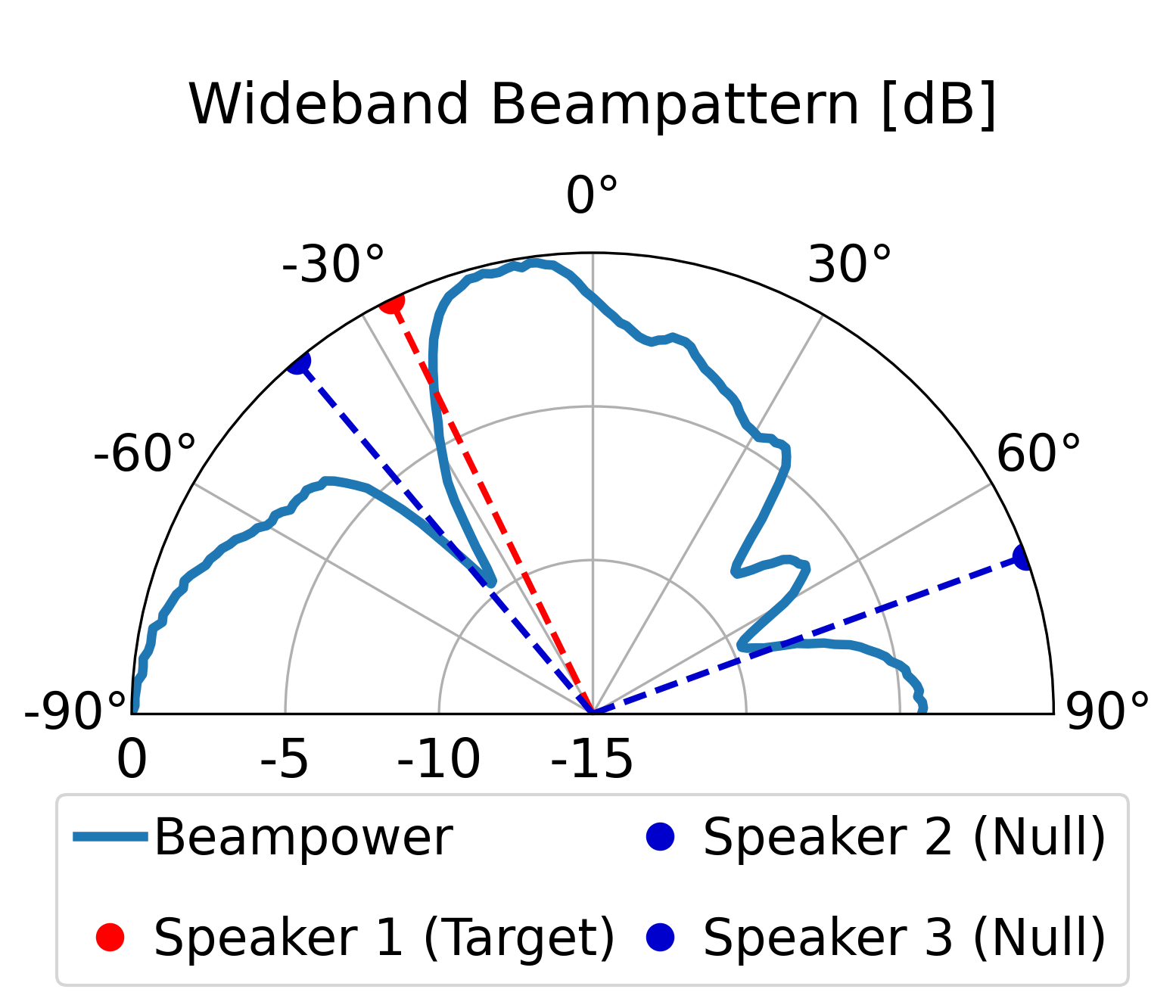
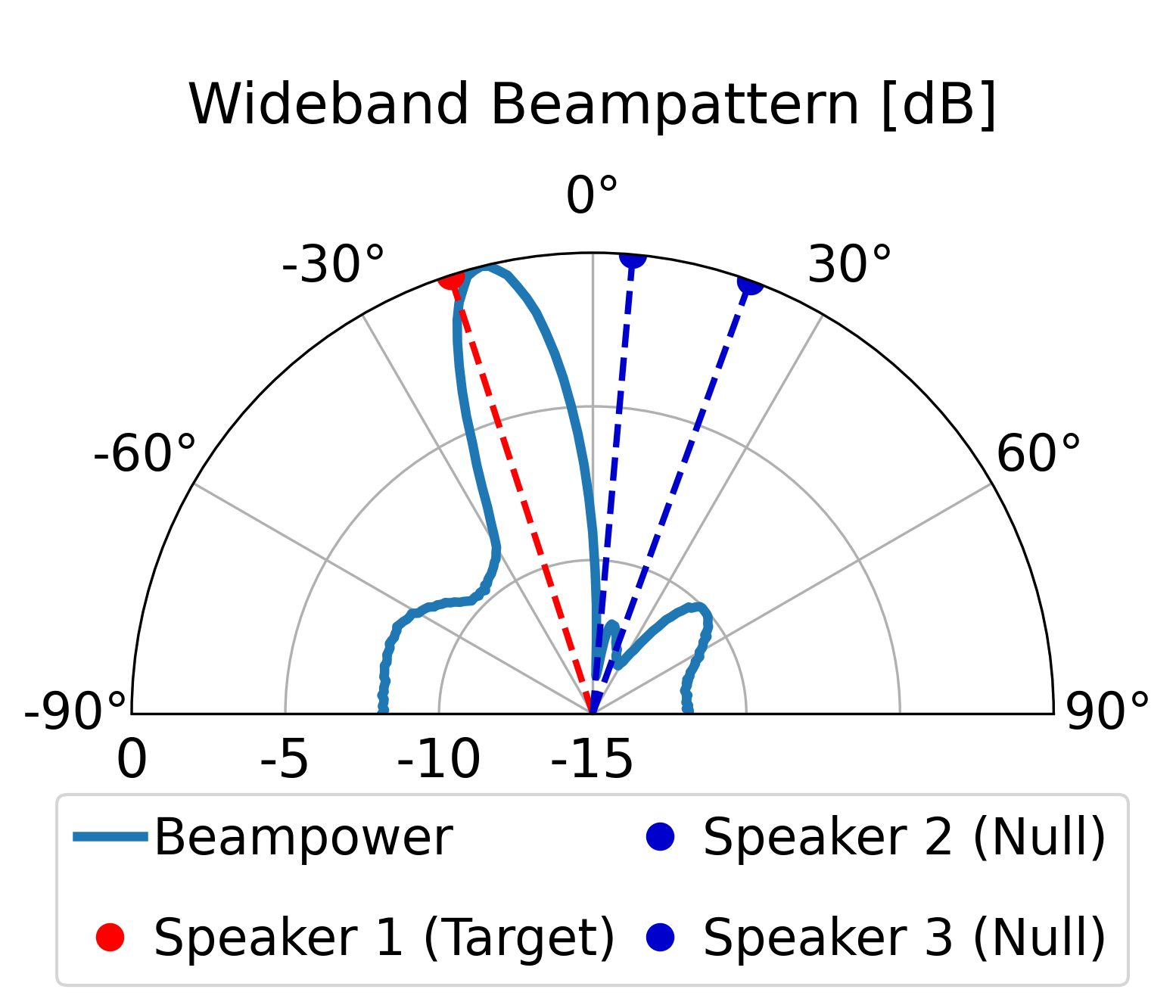
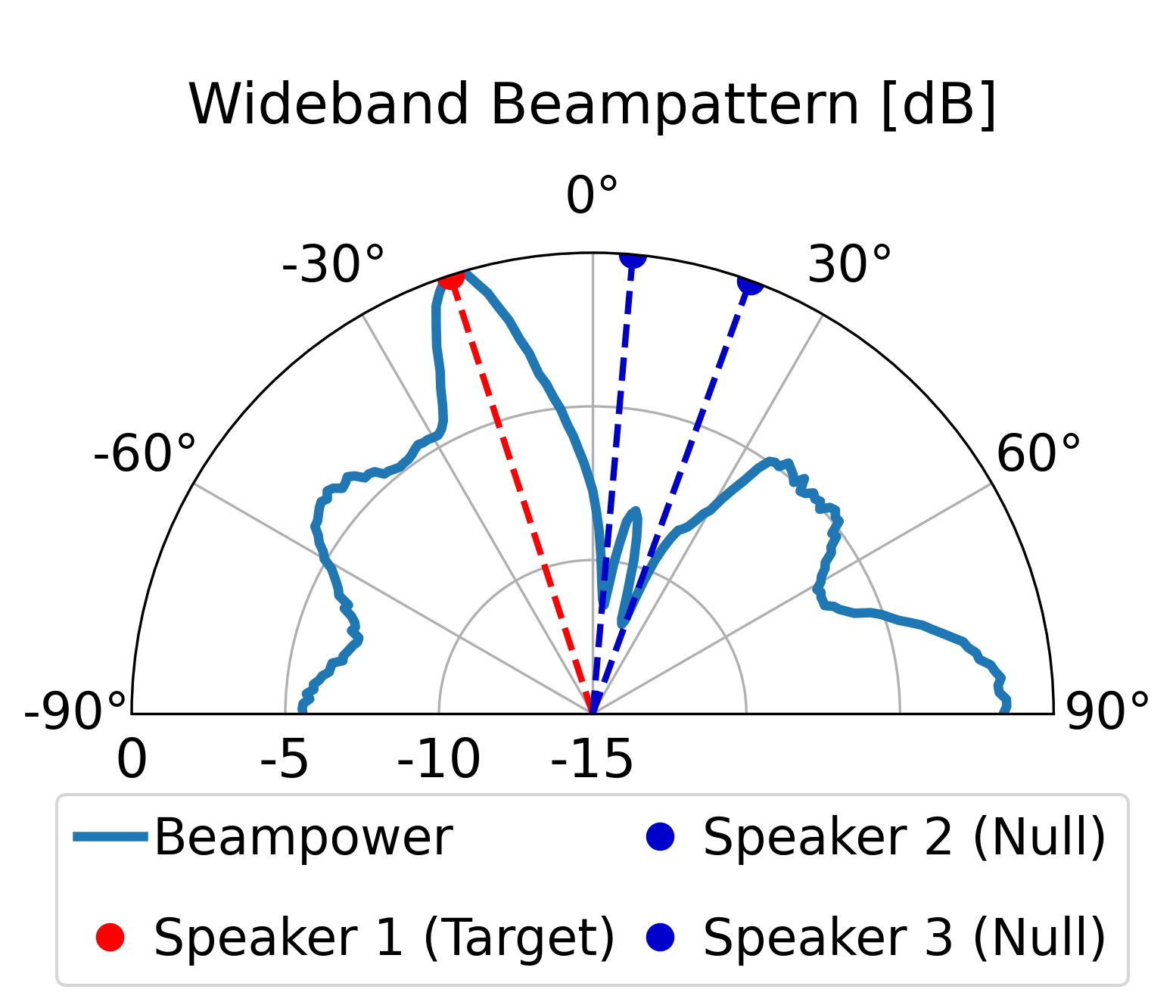
The proposed model can direct a beam toward the target speaker while directing nulls toward the
interfering sources, achieving superior overall enhancement performance compared with the classical
LCMV beamformer constructed by the same estimated spatial signatures. Furthermore, compared with the
LCMV beamformer, the proposed model produces more controlled sidelobes and improved background-noise
attenuation.
Note: We recommend listening with headphones.
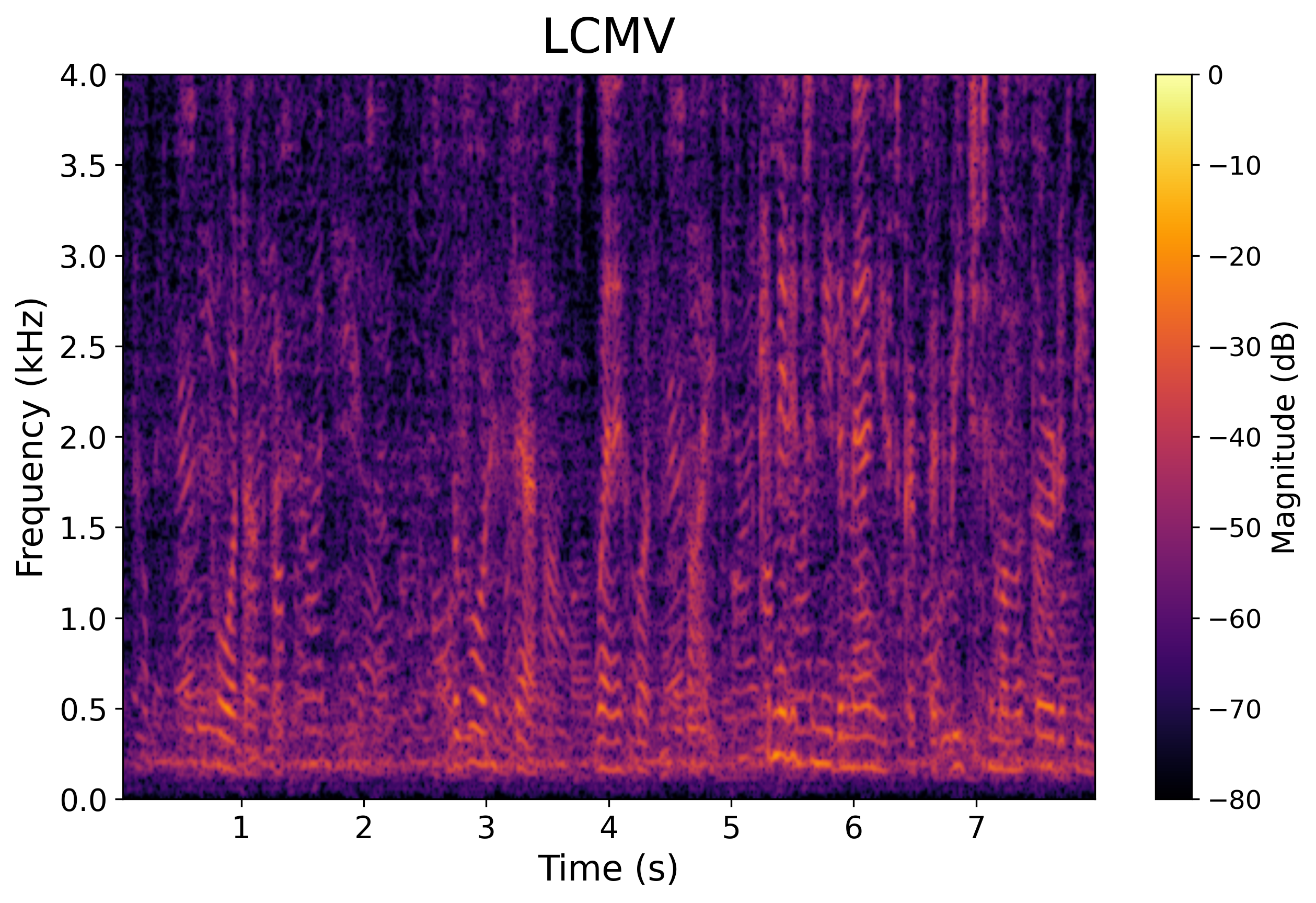
Scenario 1: Two Speakers (Anechoic / No Reverberation)
One target speaker and one interfering speaker.
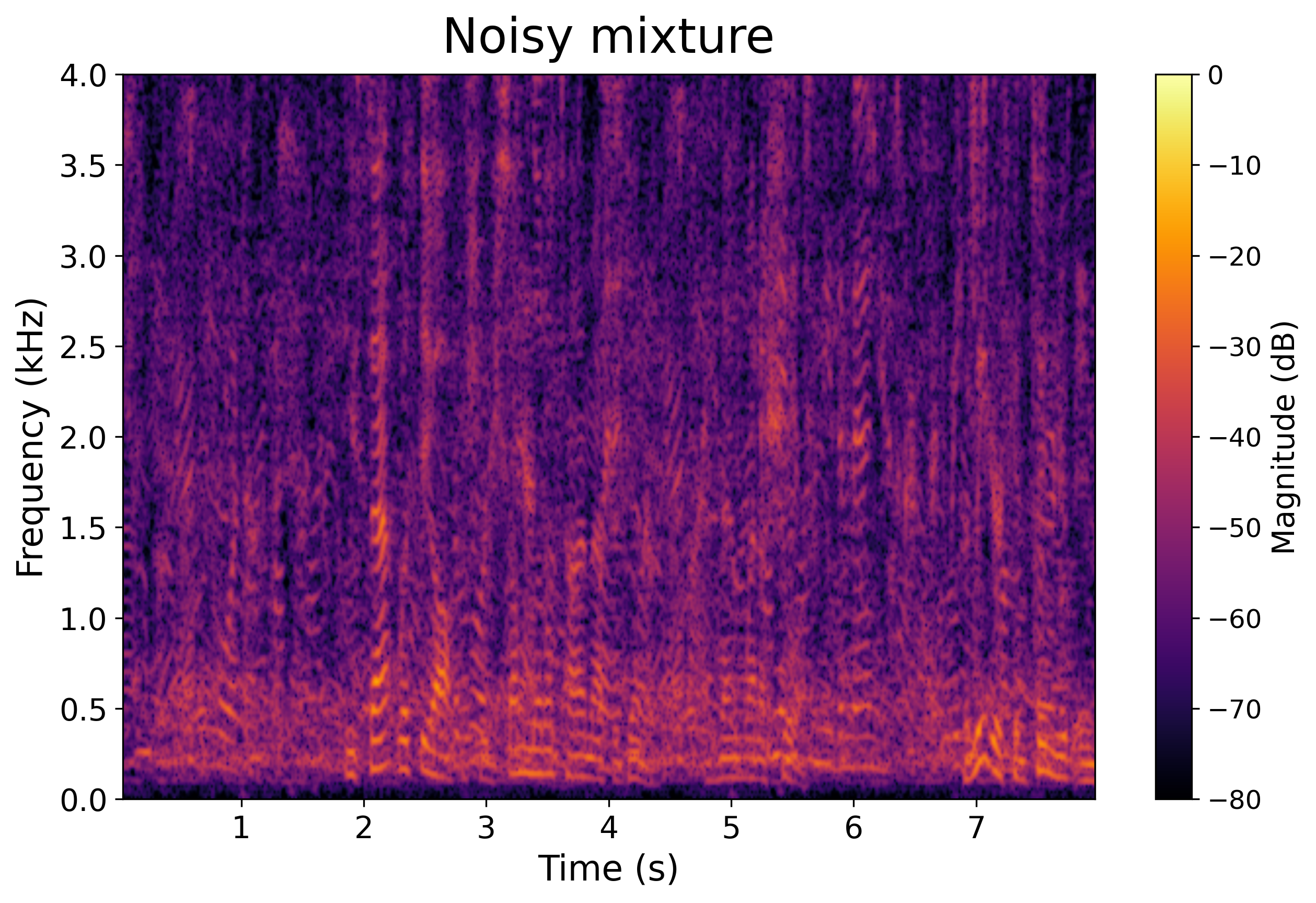
Input
Noisy Mixture
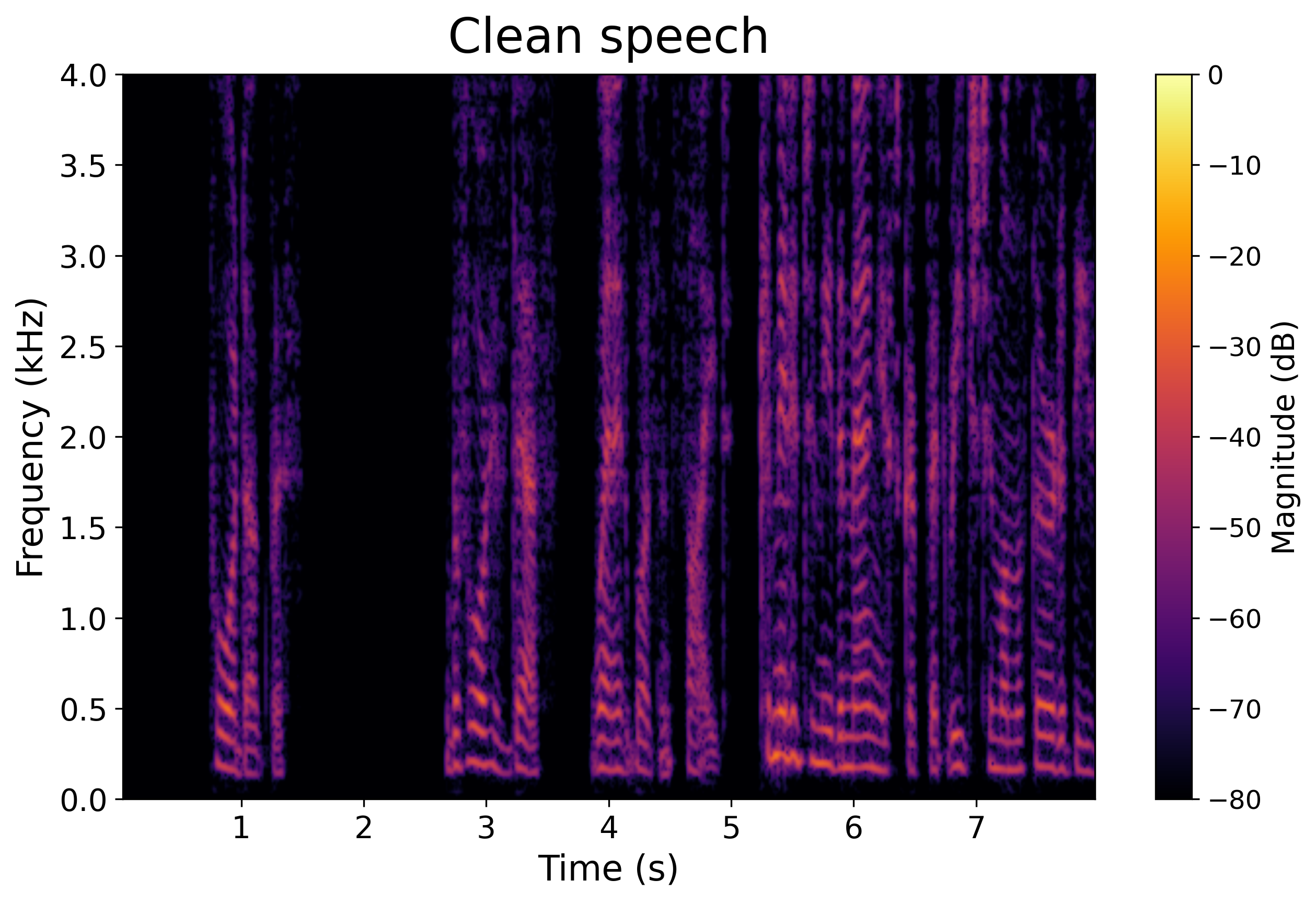
Reference
Clean Target
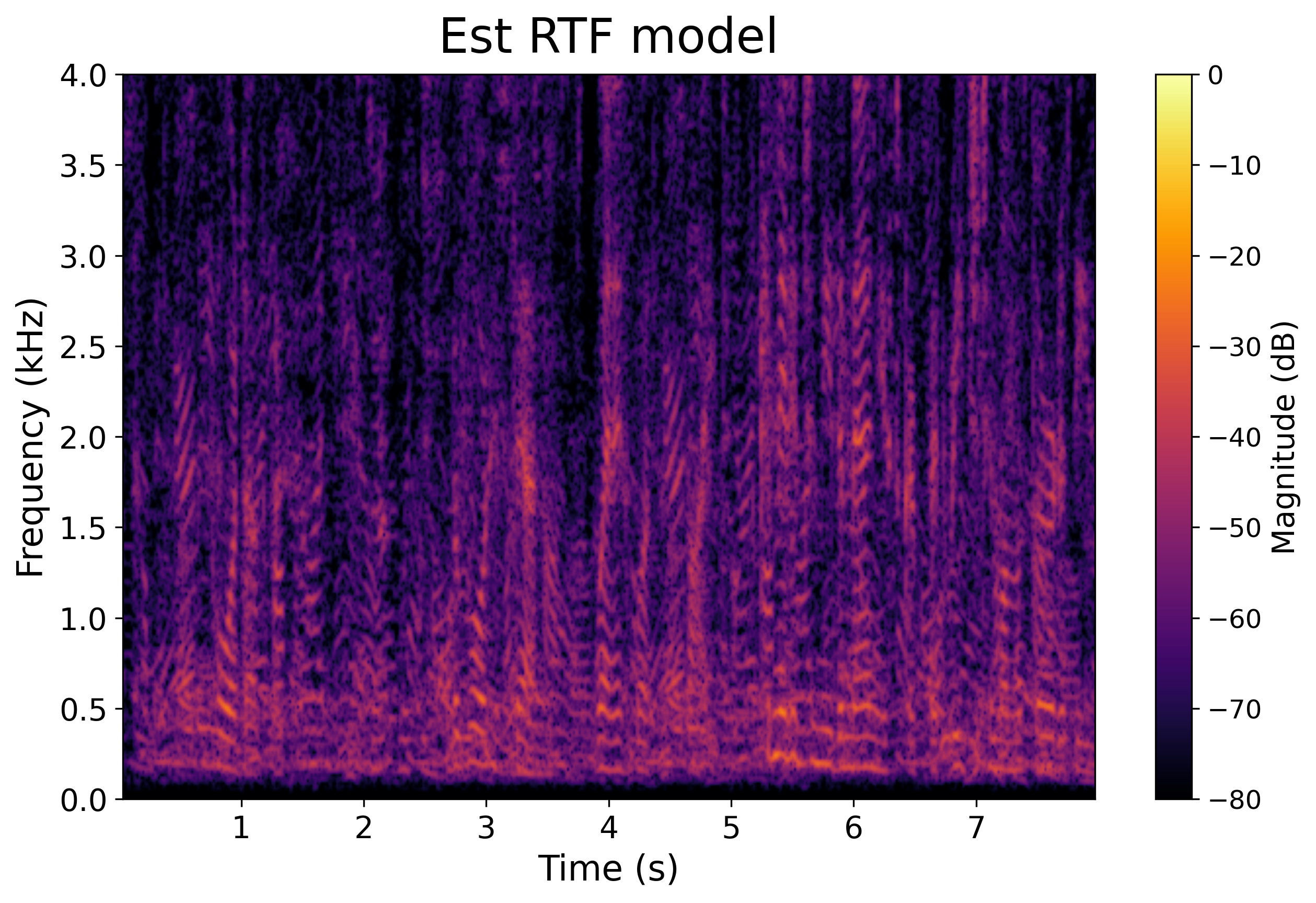
Proposed Method
Model Output (Estimated RTFs)
Baseline
LCMV Output
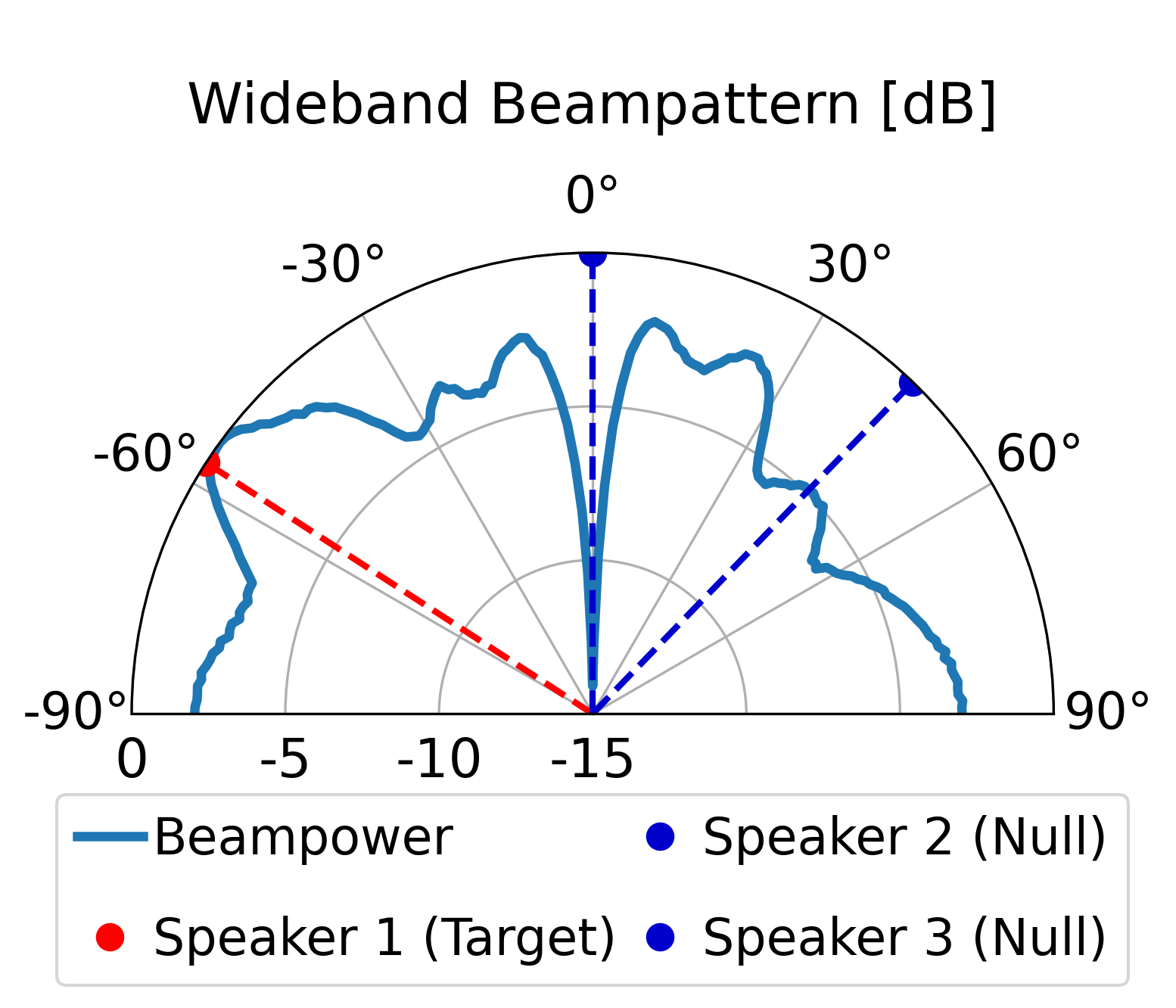
Scenario 2: Three Speakers (Anechoic / No Reverberation)
One target speaker and two interfering speakers.
Input
Noisy Mixture
Reference
Clean Target
Proposed Method
Model Output (Estimated RTFs)
Baseline
LCMV Output
Scenario 3: Two Speakers (Reverberant Environment)
Challenging room acoustics with multi-path reflections. T60 ∈ [0.3, 0.55] s.
Note: 2D polar beampatterns are omitted here, as dense multipath reflections make standard spatial plots distorted and difficult to interpret visually.
Reminder: Our objective is spatial interference suppression, not dereverberation.
Input
Noisy Mixture
Reference
Clean Target
Proposed Method
Model Output (Estimated RTFs)
Baseline
LCMV Output
Additional Beampattern Examples
Further demonstrating the spatial nulling stability across different random room geometries.